In this article, we will discuss the importance of scaling in business growth and how it can help companies stay competitive in the market. We will also explore the key differences between horizontal and vertical scaling, and their respective benefits and drawbacks. Lastly, we will provide some tips on how businesses can effectively implement scaling strategies to support their growth.

What is Scalability?
Scalability refers to the ability of a system, network, or process to handle an increasing amount of work or users in a reliable and efficient manner. It is a key characteristic of a system that allows it to adapt and grow without significant degradation in performance or stability. In other words, scalability ensures that a system can handle a larger workload or user base without crashing or slowing down. This is particularly important in modern technology, where the demand for resources and services can fluctuate greatly. A scalable system is able to seamlessly handle these fluctuations and continue to provide a high level of performance and availability.
Horizontal Cloud Scaling
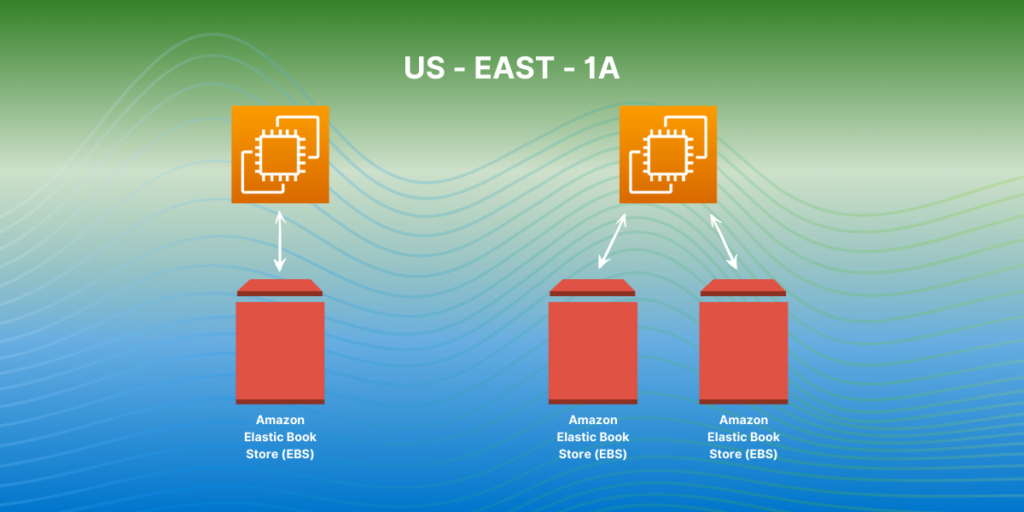
Horizontal scaling, also known as scaling out, is a technique used to increase the capacity of a system by adding more resources rather than upgrading existing ones. This is done by adding more machines or servers to handle more power of the workload, thus distributing the load across multiple nodes or systems.
Horizontal scaling refers to cloud computing and can help improve performance, reliability, and availability of a system. It is a cost-effective way to handle increasing demands and can be easily implemented by adding more resources as needed.

Explanation of Horizontal Scaling
Horizontal scaling is a method of increasing the capacity of a target resource in a system by adding more identical resources in parallel. This means that instead of increasing the power of a single resource, multiple resources are added to work together and handle a larger workload.
In horizontal scaling, the workload is distributed across multiple servers or machines, allowing for increased performance, reliability, and availability. This can be contrasted with vertical scaling, where the capacity of a single node or resource is increased by adding more resources to it.
One of the key advantages of horizontal scaling is its ability to handle sudden increases in demand. If a website or application experiences a sudden surge in traffic, additional resources can be quickly added to handle the increased load, without causing downtime or performance issues.
Another benefit of horizontal scaling is its cost-effectiveness. Instead of investing in expensive, high-powered hardware, organizations can add more affordable, lower-powered resources as needed. This also makes it easier to scale resources up or down depending on current demand, reducing unnecessary costs when you’re just starting.
However, horizontal scaling also has some limitations. It may require more complex configuration and management compared to vertical scaling. Additionally, not all applications or systems are designed to be horizontally scaled, so it may not be a viable option for all situations.
Overall, horizontal scaling is a popular choice for organizations looking to increase their system’s capacity and handle sudden spikes in demand. It offers benefits such as improved performance, scalability, and cost-effectiveness, but also requires careful planning and implementation to be effective.
Advantages of Horizontal Scaling
- Increased capacity: One of the main advantages of using a server cluster is that it can handle a larger volume of traffic and data compared to a single server. This is because a cluster can distribute the workload among multiple servers, allowing for increased capacity and performance.
- Fault tolerance: Server clusters are designed to be fault-tolerant, meaning they can continue to operate even if one or more servers experience issues. This is achieved through the use of specialized software and hardware that allows the cluster to detect and recover from failures, minimizing downtime.
- Cost-effectiveness: Server clusters can be a cost-effective solution for businesses as they allow for the distribution of workload among multiple servers, reducing the need for expensive high-end servers. This also means that if one server needs to be upgraded or replaced, it can be done without disrupting the entire system.
Implementation strategies
- Load balancing is a technique used to distribute the workload evenly across multiple nodes in a network. This can be implemented by using a load balancer, which acts as a traffic controller and distributes incoming requests to different servers based on their current load and availability.
- Clustering is a method of grouping multiple servers to act as a single system. This is achieved by using clustering software that allows the servers to communicate with each other and work together to perform a task. This helps in achieving high availability, scalability and fault tolerance.
- Distributed computing is a model in which a task is divided into smaller subtasks and distributed across multiple nodes in a network. These nodes then work together to complete the task, thereby reducing the overall processing time. This approach is ideal for handling large and complex tasks that require significant computing power.
Real-world use case examples
- Social Media Platforms: Popular social media platforms like Facebook, Twitter, and Instagram use horizontal scaling to handle the millions of users accessing their platforms simultaneously. By adding more servers, they are able horizontally scale to handle the increased demand and keep the platform running smoothly.
- E-commerce Websites: Online retailers like Amazon and eBay use horizontal scaling to handle the large volume of transactions and visitors to their websites. By adding more servers, they can handle the increased traffic and ensure fast and reliable service for their customers.
- Cloud Computing: Cloud computing providers like Amazon Web Services and Microsoft Azure use horizontal scaling to handle the growing demand for their services. By adding more servers and resources, they can handle the increased number of customers and provide reliable and scalable services.
- Video Streaming Services: Services like Netflix and Hulu use horizontal scaling to deliver high-quality streaming to their millions of subscribers. By adding more servers, they can handle the large amount of data transfer required for streaming videos to multiple users at the same time.
- Online Gaming: Online gaming companies like Blizzard and Riot Games use horizontal scaling to handle the large number of players accessing their games simultaneously. By adding more servers, they can ensure a smooth and uninterrupted gaming experience for their players.
Vertical Cloud Scaling
Vertical scaling, also known as “scaling up” or “scaling vertically”, refers to the process of increasing the resources (such as CPU, memory, and storage) of a single server or machine. This is typically done by upgrading the hardware components of the server, such as adding more RAM or a faster CPU.
Vertical scaling means it is often used to improve the performance and capacity of a single server, for example allowing it to handle more users or process more data. It is usually a more cost-effective solution than horizontal scaling, which involves adding more servers to a system.

Explanation of Vertical Scaling
Vertical scaling refers to increasing the capacity or performance of a single server or computer system. It involves adding more resources such as RAM, CPU, storage, and bandwidth to the existing server or system to handle increased workload and traffic.
Vertical scaling is typically done by upgrading the hardware components of a single machine or server, such as adding more RAM or replacing the existing CPU with a more powerful one. This allows the system to handle a larger amount of data and perform more complex tasks at a faster rate.
One of the main advantages of vertical scaling to point out is that it is relatively easy to implement, as it only requires adding more resources to an existing system. This can be done by simply upgrading the hardware or by migrating to a more powerful server.
However, there are also limitations to making vertical scale. Eventually, a server or system will reach its maximum capacity and resource usage and can no longer be scaled up. At this point, businesses may need to consider other options such as horizontal scaling, which involves adding more servers to distribute the workload.
In summary, vertical scaling is the process of increasing the performance and capacity of a single server or system by adding more resources. It is a simple and efficient way to handle increased workload and can be a cost-effective solution for businesses. However, it also has its limitations, and businesses may need to explore other options as their needs continue to grow.
Advantages of Vertical Scaling
- Simplicity: Vertical scaling involves increasing the resources of a single server, such as adding more CPU, memory, or storage. This makes it a simpler and more straightforward process compared to horizontal scaling, which requires adding multiple servers.
- Fewer synchronization issues: With vertical scaling, all the resources are located on a single server, which reduces the need for synchronization between different servers. This minimizes the risk of data inconsistencies and ensures smooth operation of the application.
- Scalability for certain applications: Vertical scaling is more suitable for applications that require high processing power, such as databases, analytics, and scientific computing. These applications can benefit from the increased resources of a single server, without the need for complex clustering or load balancing.
Implementation strategies
- Upgrading hardware: This involves replacing old hardware components with newer and more powerful ones. This can include upgrading the processor, memory, storage, and network equipment. Upgrading hardware can improve system performance, increase storage capacity, and allow for more efficient resource utilization and allocation.
- Optimizing software: Software optimization involves streamlining and improving the performance of existing software. This can include optimizing code, removing unnecessary features, and improving data processing algorithms. Optimizing software can improve system speed and efficiency, reduce resource usage, and enhance overall system performance.
- Virtualization: Virtualization involves creating virtual versions of hardware and software resources. This allows for better utilization of hardware resources, as multiple virtual machines can run on a single physical server. Virtualization can also improve system scalability and flexibility, as resources can be easily allocated and reallocated as needed.
Vertical scaling examples
- Increasing the processing power of a server: One common example of vertical scaling is increasing the processing power of a server. This can involve adding more powerful CPUs, increasing the RAM, or upgrading to a higher tier of hardware. This allows the server to handle a larger volume of requests and improve overall performance.
- Upgrading computer components: When a computer starts to feel sluggish or cannot run certain programs, users may choose to upgrade its components through vertical scaling. This can include adding more RAM, upgrading the CPU, or installing a more powerful graphics card. These upgrades can significantly improve the computer’s performance and allow it to handle more demanding tasks.
- Scaling up a virtual machine: In cloud computing, vertical scaling refers to up a virtual machine involves increasing its resources, such as CPU, RAM, and storage, to handle increased workloads. This allows the virtual machine to handle more tasks and users without experiencing performance issues.
- Expanding database capabilities: As a business grows, its database needs may also increase. Vertical scaling can be used to expand a database’s capabilities by adding more storage, increasing the number of concurrent connections, and improving processing power. This allows the database to handle larger amounts of data and improve its performance.
- Upgrading a smartphone’s hardware: When a smartphone starts to feel slow or cannot run certain apps, users may choose to upgrade its components through vertical scaling. This can include increasing the RAM, storage, or upgrading to a newer and more powerful model. These upgrades can improve the phone’s performance and allow it to handle more demanding tasks.
Factors Influencing the Choice
- Compatibility with existing systems and software;
- Security and data privacy concerns;
- Availability of support and maintenance services;
- Integration with other tools and platforms;
- User interface and ease of use;
- Performance and speed requirements;
- Reliability and uptime guarantees;
- Flexibility and customization options;
- Vendor reputation and customer reviews;
- Regulatory compliance requirements;
- Migration and transition plans;
- Training and learning curve for employees;
- Contract terms and service level agreements;
- Industry-specific needs and regulations;
- Geographic location and data sovereignty laws.
Best Practices
- Conduct thorough performance analysis: Before implementing any scaling strategies, it is important to thoroughly analyze the current performance of your system. This will help identify any bottlenecks or areas that may need improvement before scaling can be effective.
- Consider scalability from the outset: When designing and building your system, it is important to keep scalability in mind from the beginning. This means using technologies and architectures that can easily accommodate growth without major reworking.
- Implement monitoring and automation: Monitoring the performance of your system is crucial in identifying when scaling is needed. Automation tools can also help automatically scale resources up or down based on predefined thresholds, reducing the need for manual intervention.
- Regularly review and reassess scaling strategy: As your system and business needs evolve, it is important to regularly review and reassess your scaling strategy. This will ensure that it remains effective and efficient in meeting the demands of your growing user base.
Conclusion
Horizontal cloud scaling, also known as scaling out, involves adding more machines or nodes to a system to increase its capacity. This is achieved by distributing the workload across multiple machines, allowing for better performance and handling of increased traffic.
Vertical cloud scaling, also known as scaling up, involves upgrading the existing hardware or infrastructure to increase its capacity. This is achieved by adding additional machines or more resources, such as memory, CPU, or storage, to an existing machine.
Both, horizontal scalability and vertical scaling have their own advantages and disadvantages. Horizontal scaling allows for better fault tolerance and scalability, as the workload is distributed across multiple machines. However, it requires a more complex system architecture and may not always result in a linear increase in performance.
Vertical scaling, on the other hand, may be more cost-effective and easier to implement initially. However, it may not be as scalable in the long run as horizontal, and can result in a single point of failure if the upgraded hardware fails.
Choosing the right vertical scaling and horizontal out strategy depends on various factors, such as the type of web service or application, expected growth, budget, and existing infrastructure. It is important for businesses to carefully evaluate their needs and consider the trade-offs before deciding on a scaling strategy.
In addition, businesses should also consider implementing a hybrid approach, where both horizontal and vertical scaling are used together. This allows for a more flexible and robust system, as both strategies complement each other.
Other important considerations for businesses include regularly monitoring and testing their scaling strategy to ensure it is meeting their needs. They should also be prepared to adapt and adjust their strategy as their needs and requirements change.
In conclusion, choosing the right scaling strategy is crucial for businesses to ensure their systems can handle increased traffic and maintain optimal performance. It requires careful evaluation and consideration of various factors, and businesses should also be prepared to adapt and adjust their strategy as needed. By choosing the right scaling strategy, businesses can ensure their systems are scalable, reliable, and can support their growth and success.
FAQs
What are the challenges or limitations of horizontal scaling?
- There is a limit to how much an application can be horizontally scaled, as it requires additional hardware and resources to add more servers.
- There may be issues with data consistency and synchronization across multiple servers, which can affect the performance and reliability of the application.
- Not all applications are designed to be horizontally scalable, and it may require significant changes to the architecture or codebase.
- Load balancing and managing multiple servers can be complex and requires additional resources and expertise.
- It may not be cost-effective for smaller applications, as the cost of hardware and maintenance can add up quickly.
What are the challenges or limitations of vertical scaling?
- There is a limit to how much an application can be vertically scaled, as the resources of a single server are finite.
- It can be challenging to upgrade or replace hardware in a live production environment, as it may cause downtime or disruption to the application.
- There may be compatibility issues when upgrading to newer or different hardware components.
- It may not be cost-effective in the long run, as the cost of high-end hardware can be expensive.
Is it cheaper to scale horizontally or vertically?
The cost of vertical and horizontal scaling depends on the scale based on various factors, such as the size and complexity of the application, the resources needed, and the availability of hardware.
So what are the key differences, shortly?
So let’s sum up everything based on key differences. Horizontal scaling can be more cost-effective in the long run than vertical scaling, as it allows for adding resources as needed, rather than investing in expensive high-end hardware for vertical scaling. However, this may not always be the case, and the most cost-effective option will vary depending on the scale of web server, the specific application and its requirements.