FinOps best practices are essential for organizations aiming to manage cloud expenses effectively while maximizing business value. As cloud adoption grows, businesses face increasing challenges in optimizing costs without compromising performance. Without a structured approach, cloud spending can escalate, leading to inefficiencies and budget overruns.
This is where FinOps (Financial Operations) plays a critical role. It is a collaborative discipline that integrates finance, engineering, and business teams to ensure financial accountability and optimize cloud investments. FinOps enables organizations to shift from reactive cost-cutting to proactive cost optimization, aligning cloud usage with business goals.
In this article, we’ll explore FinOps best practices, focusing on actionable insights that help businesses control cloud costs while maintaining agility. Whether your infrastructure runs on AWS, Azure, or Google Cloud, applying FinOps principles helps pinpoint wasteful spending, optimize resource allocation, and enforce financial accountability.
What is FinOps?
FinOps (Financial Operations) is a cloud financial management approach that helps businesses achieve cost efficiency while maintaining performance and scalability. Unlike traditional IT budgeting, FinOps embraces the dynamic, usage-based cost model of cloud computing, ensuring that costs are tracked, optimized, and aligned with business objectives.
Core Principles of FinOps
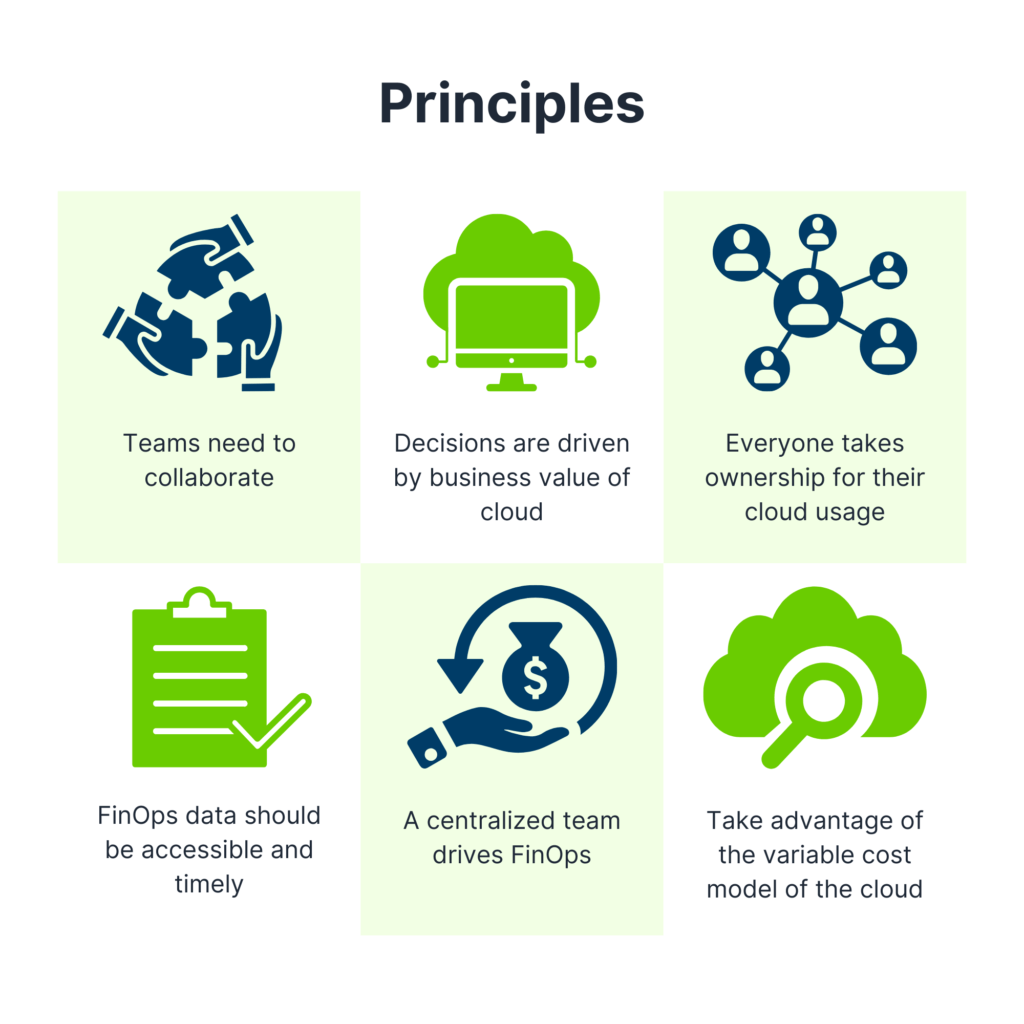
Successful FinOps practices are built on six key principles that help organizations manage cloud costs effectively:
Teams Need to Collaborate – Cloud cost management is a shared responsibility across finance, engineering, and business teams. Cross-functional collaboration ensures that spending decisions balance cost and performance.
Decisions Are Driven by Business Value – Cloud investments should be justified by measurable business impact, not just cost-cutting.
Everyone Takes Ownership of Their Cloud Usage – Engineers, finance, and operations teams are accountable for their cloud consumption and optimizations.
FinOps Reports Should Be Accessible and Timely – Real-time cost visibility enables proactive decision-making rather than reacting to monthly invoices.
A Centralized Team Drives FinOps Best Practices – While all teams contribute to cost management, a dedicated FinOps function ensures governance and policy enforcement.
Take Advantage of the Cloud’s Variable Cost Model – Cloud pricing is dynamic, and FinOps promotes autoscaling, reserved instances, and commitment-based discounts to optimize costs.
By applying these principles, organizations can transition from uncontrolled cloud expenses to a data-driven, optimized cost management strategy.
Key FinOps Best Practices for Cloud Cost Management
FinOps best practices are structured within FinOps capabilities, and categorized into key domains ensuring an efficient and measurable approach to cloud cost management. Rather than listing every capability, we’ll highlight the most impactful practices that deliver immediate value.
Build a FinOps Culture Across Teams
One of the foundational FinOps best practices is fostering a culture of collaboration where finance, IT, and business teams work together. Managing cloud costs requires more than just financial oversight – it involves cross-functional alignment to ensure cost efficiency without sacrificing performance.
Foster Collaboration Between Finance, IT, and Business Units
- Finance teams gain real-time visibility into cloud spending, improving budgeting accuracy.
- IT and engineering teams get actionable insights to optimize workloads and prevent unnecessary spending.
- Business leaders ensure that cloud investments align with strategic objectives and revenue goals.
FinOps encourages ongoing collaboration, making cost management an integrated, continuous practice rather than an afterthought.
Define Clear Roles and Responsibilities
A well-structured FinOps practice includes clearly defined roles:
- FinOps Lead – Oversees financial governance and ensures strategy alignment.
- Cloud Engineers & DevOps – Optimize resources, eliminate waste, and implement automation.
- Finance & Procurement – Monitor budgets, forecast spending, and set financial controls.
- Executives & Business Leaders – Set cost efficiency goals and oversee high-level cloud spending decisions.
Establishing these roles ensures that FinOps implementation remains a continuous, company-wide effort.
Set Budgets and alerts
A core aspect of FinOps cost management is defining budgets and cost allocation strategies to prevent unexpected expenses. Organizations should proactively allocate spending limits and monitor them in real time.
- Define cost limits for teams, projects, and workloads.
- Use cloud provider tools like AWS Budgets, Azure Cost Management, and Google Cloud Billing for tracking.
- Enable real-time alerts for spending anomalies or unexpected cost spikes.
- Regularly review and adjust budgets based on cloud usage trends.
Budgeting within FinOps ensures cloud costs remain predictable, preventing budget overruns and inefficient spending.
Optimize Resource Usage
Many organizations over-provision cloud resources, leading to unnecessary expenses. FinOps emphasizes continuous optimization by rightsizing infrastructure and eliminating inefficiencies.
Rightsize Instances and Storage
- Analyze usage metrics to detect underutilized compute, memory, and storage.
- Scale down oversized instances or migrate workloads to more cost-effective options.
- Use tiered storage solutions (e.g., S3 Glacier, Azure Cool Storage) for infrequently accessed data.
Use Reserved Instances and Autoscaling Effectively
- Rate Optimization & Licensing – Leverage Reserved Instances (RIs) and Savings Plans for predictable workloads.
- Autoscaling & Spot Instances – Use spot pricing for non-critical workloads to reduce costs.
Automate Cost Optimization
Automating cost management reduces manual effort while ensuring continuous optimization.
- Idle Resource Detection – Tools like AWS Trusted Advisor and Google Cloud Recommender help identify unused resources.
- Scheduled Shutdowns – Automate turning off non-production workloads during off-hours.
- Automated Data Lifecycle Management – Implement backup automation and storage tiering to optimize storage costs.
Track and Measure Key Metrics
Tracking Key Performance Indicators (KPIs) is crucial for understanding cloud financial performance. The FinOps Foundation provides a KPI Library (FinOps KPI Library) to guide businesses in selecting relevant metrics.
Each FinOps practice has specific KPIs, but the ones you need depend on your business goals, cloud infrastructure, and FinOps maturity level.
Conclusion
A well-executed FinOps strategy empowers businesses to maintain financial discipline while maximizing the value of their cloud investments. By adopting FinOps best practices, organizations can gain visibility into cloud costs, drive accountability across teams, and make data-driven decisions that balance cost and performance. By integrating collaborative cost management, proactive budgeting, continuous resource optimization, automation, and real-time KPI tracking, organizations can shift from reactive cost control to a more strategic approach that ensures long-term financial sustainability.
FinOps is not just about cutting expenses – it is about enabling smarter, more efficient cloud spending that aligns with business goals and fosters innovation. By continuously refining FinOps practices, companies can maintain agility, control costs, and optimize their cloud infrastructure for sustained success.