AWS EventBridge is a powerful event-driven service that allows developers to create highly scalable, event-driven architectures in the cloud. In recent years, event-driven architecture (EDA) has become increasingly popular in the world of cloud computing. This approach to building software systems is based on the concept of events – discrete occurrences that trigger actions or processes within an application.
In an event-driven architecture, different components of an application communicate through events, enabling a more loosely coupled and scalable system. This allows for a more flexible and resilient approach to building applications, as different components can react and respond to events in real-time.
AWS EventBridge is a fully managed event bus service that integrates with a wide range of AWS services and third-party applications. It simplifies the process of building event-driven architectures by providing a centralized event bus, event routing, and event filtering capabilities.
The purpose of this article is to provide a comprehensive understanding of AWS EventBridge. We will explore its key features, use cases, and benefits, as well as how it fits into the larger landscape of event-driven architecture in modern cloud computing. By the end of this article, readers will have a thorough understanding of how to leverage AWS EventBridge to build highly scalable and event-driven applications in the cloud. So, let’s dive in!
What is AWS EventBridge?
Amazon EventBridge is a serverless event bus service provided by Amazon. It allows developers to build event-driven architectures and integrate various AWS services, SaaS applications, and custom applications.
EventBridge is a serverless event bus that processes events from various event sources such as Amazon CloudWatch, Amazon SNS, AWS Lambda, API Gateway, and more. Developers can use EventBridge to route events to specific AWS services like Lambda functions, SQS, and Step Functions.
EventBridge provides a schema registry to define the structure of the event data and content-based event filtering to route events based on their content.
Event-driven Architecture Fundamentals
Event-driven architecture is a powerful design pattern that enables the creation of scalable, real-time data integrations using AWS services. At its core, the architecture revolves around the concept of events, which trigger actions in response to specific occurrences. To implement event-driven architecture using AWS, developers can leverage services such as EventBridge, which serves as a central hub for event ingestion and processing. EventBridge supports custom events, event patterns, and event integration with a variety of AWS applications and services. It is natively integrated with services like AWS Lambda functions, making it easier to build event-driven applications or services.
Additionally, EventBridge simplifies the process of integrating with external sources by providing a scalable event bus that enables seamless communication between different systems. The EventBridge schema registry stores the structure of incoming events, ensuring that data is properly interpreted and processed by downstream applications. By directly integrating with a variety of AWS services and with built-in event sources, EventBridge makes it easy to exchange data in real-time and connect with SAAS applications via event patterns.
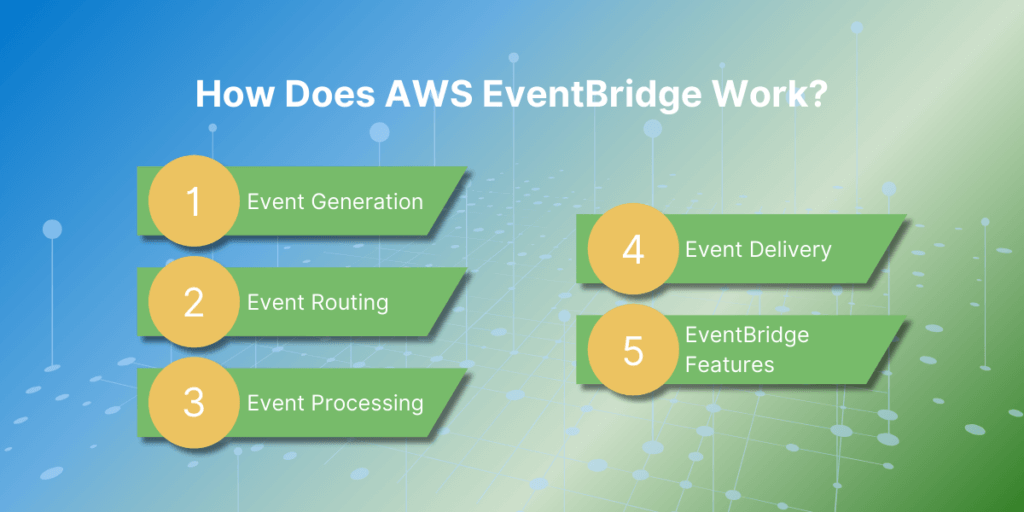
How Does AWS EventBridge Work?
Here is a step-by-step explanation of how AWS EventBridge works:
- Event Generation: The first step in the EventBridge process is event generation. Events can originate from different sources, such as AWS services, custom applications, or SaaS applications. These events can be triggered by a specific action, such as a new file being uploaded to an Amazon S3 bucket, or they can be scheduled events, such as a daily backup job.
- Event Routing: Once an event is generated, it is sent to the EventBridge service. EventBridge acts as a central hub for all events and routes them to their designated targets. This routing is based on rules that are set up by the user. These rules specify which events should be sent to which targets based on certain criteria, such as event type or source.
- Event Processing: After an event is routed to its target, it is processed according to the designated action. For example, if the target is an AWS Lambda function, the event will trigger the function to execute a specific code. If the target is an SQS queue, the event will be stored in the queue for later processing.
- Event Delivery: Once the event is processed, EventBridge delivers a response to the source of the event. This response can include information about the success or failure of the event processing, which helps to track the status of events and troubleshoot any issues.
- EventBridge Features: EventBridge offers several features to help manage events efficiently. These include event filtering, event transformation, and event replay. Event filtering allows users to specify which events should be routed to which targets, while event transformation allows users to modify the event data before it is sent to the target. Event replay allows users to replay past events in case of any failures or missed events.
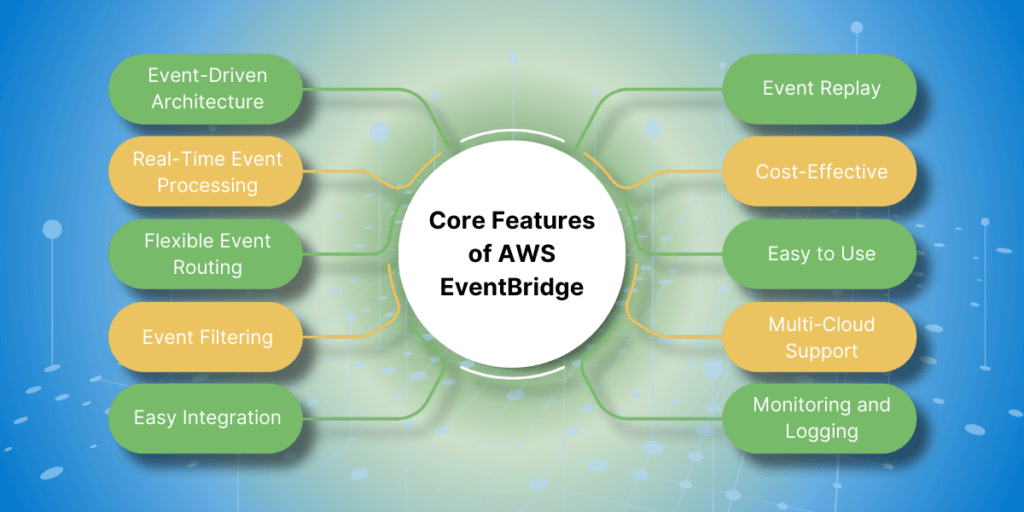
Core Features of AWS EventBridge
- Event-Driven Architecture: AWS EventBridge is designed to support event-driven architecture by allowing you to create event-based workflows and integrations. This means that actions are triggered by events, instead of being scheduled or manually initiated.
- Real-Time Event Processing: EventBridge can process events in real-time, allowing you to quickly respond to changes and updates in your environment. This makes it ideal for applications that require real-time data processing, such as streaming analytics and real-time monitoring.
- Flexible Event Routing: With EventBridge, you can easily route events to multiple targets, such as AWS Lambda functions, Amazon SNS topics, and Amazon SQS queues. This allows for greater flexibility and scalability in your event-based workflows.
- Event Filtering: EventBridge allows you to filter events based on specific criteria, such as event source, event content, and event time. This helps you to manage and process only the events that are relevant to your applications.
- Easy Integration: EventBridge integrates seamlessly with other AWS services, as well as third-party applications and services. This makes it easy to incorporate event-based workflows into your existing infrastructure.
- Event Replay: With EventBridge, you can replay events from the past 24 hours, making it easy to test and troubleshoot your event-based workflows. This can also be useful for recovering from errors or failures.
- Cost-Effective: EventBridge follows a pay-per-event pricing model, which means you only pay for the events that are processed by the service. This makes it a cost-effective solution for event-driven applications.
- Easy to Use: EventBridge is easy to set up and use, with a simple interface and intuitive features. This allows developers to quickly create event-based workflows without a steep learning curve.
- Monitoring and Logging: EventBridge provides detailed monitoring and logging capabilities, allowing you to track the performance of your event-based workflows and troubleshoot any issues that may arise.
Integration with AWS services
Amazon Web Services (AWS) offers a wide range of cloud computing services that can be integrated with other applications and services. This allows for a more efficient and seamless flow of data between different systems, as well as providing access to powerful tools and features that can enhance the functionality of your application.
Some of the most popular AWS services that can be integrated with other applications include:
- Amazon S3 (Simple Storage Service): This service allows for secure and scalable storage of data in the cloud. It can be integrated with applications to store and retrieve data, such as user files, media, and backups.
- Amazon EC2 (Elastic Compute Cloud): This service provides virtual servers, known as instances, that can be used to run applications. It can be integrated with other services to provide a scalable and reliable infrastructure for your application.
- Amazon RDS (Relational Database Service): This service allows for the creation and management of relational databases in the cloud. It can be integrated with applications to store and retrieve data, such as user profiles, product information, and more.
- Amazon API Gateway: This service allows for the creation, management, and deployment of APIs. It can be integrated with applications to enable secure and efficient communication between different systems.
- Amazon Lambda: This service allows for the execution of code in response to events or triggers. It can be integrated with applications to automate tasks and processes, such as data processing or sending notifications.
- Amazon CloudWatch: This service provides monitoring and logging capabilities for your AWS resources. It can be integrated with applications to track and analyze performance metrics, as well as set up alerts and notifications.
- Amazon SES (Simple Email Service): This service allows for the sending and receiving of email messages. It can be integrated with applications to send transactional or marketing emails to customers.
- Amazon SNS (Simple Notification Service): This service allows for the sending and receiving of push notifications to mobile devices. It can be integrated with applications to send real-time updates and notifications to users.
Schema registry and discovery
Schema registry and discovery are two crucial components in the world of data management and integration. The schema registry serves as a centralized repository for storing and managing data schemas, ensuring consistency and compatibility across systems. On the other hand, discovery enables the automatic detection and sharing of data schemas, making it easier for applications to communicate with each other. Together, these two tools play a vital role in simplifying data integration and promoting data interoperability in complex environments.
Implementing AWS EventBridge
- Create an EventBridge rule: To create an EventBridge rule, go to the AWS EventBridge console and click on the “Create rule” button. Give your rule a name and description, and then choose the event source. This can be an AWS service, a custom event bus, or an external event source. You can also choose to filter events based on specific criteria.
- Configure targets: Next, you will need to configure the targets for your rule. These are the actions that will be performed when an event is received by the rule. You can choose from a variety of targets, such as Lambda functions, SNS topics, or Step Functions.
- Set permissions: To allow your rule to send events to the chosen targets, you will need to set permissions. This can be done by creating a new IAM role or using an existing one.
- Test your rule: Once your rule is created and configured, you can test it by sending test events to it. This will allow you to see if your rule is triggering the desired actions.
- Monitor your rule: You can monitor the execution of your rule and the events it receives by going to the EventBridge console and viewing the rule’s dashboard. This will show you the number of events received, any errors, and the status of the targets.
- Manage and update your rule: You can manage and update your rule as needed by going to the EventBridge console and selecting your rule. From here, you can edit the rule, add or remove targets, and change the event source or filtering criteria.
- Automate with CloudFormation: To easily deploy and manage multiple EventBridge rules, you can use AWS CloudFormation. This allows you to define your rules in a template and easily deploy them to different environments.
- Use EventBridge with other AWS services: EventBridge can be integrated with other AWS services, such as AWS Lambda, Amazon SNS, Amazon SQS, and more. This allows for more complex and automated event-driven workflows.
Best Practices for Using AWS EventBridge
- Design Considerations for Event-Driven Architectures – іdentify the events and triggers. Start by defining the events that your system needs to respond to and identify the triggers that will initiate those events. This will help in designing a clear and efficient event-driven architecture.Choose the right event source: AWS EventBridge supports various event sources such as AWS services, custom applications, and SaaS providers. Choose the event source that best fits your use case.Design for scalability and fault tolerance: As your system grows, the number of events and triggers will increase. Design your architecture to handle this growth and ensure that it is fault-tolerant to handle any failures.Use event schemas: EventBridge allows you to define event schemas that can be used to validate the incoming events. Use schemas to ensure that the events are in the expected format and avoid processing invalid events.Consider event delivery guarantees: EventBridge offers two delivery guarantees – at least once and exactly once. Choose the delivery guarantee based on the criticality of your events and the impact of duplicate events.
- Security and Permissions – use IAM roles and policies. EventBridge integrates with AWS Identity and Access Management (IAM) to control access to resources. Use IAM roles and policies to grant permissions to users and services that need to access EventBridge.Enable encryption: Enable server-side encryption for your event bus to ensure that your events are always encrypted at rest.Use AWS KMS: Use AWS Key Management Service (KMS) to manage the encryption keys used by EventBridge. This ensures that you have full control over the encryption keys and can manage them centrally.Use resource policies: EventBridge supports resource policies that allow you to control access to your event buses at a more granular level. Use resource policies to restrict access to specific event buses to specific IAM users or roles.
- Monitoring and Troubleshooting Tips – use CloudWatch Metrics. EventBridge automatically publishes metrics to CloudWatch, which can be used to monitor the health of your event buses and rule executions. Use these metrics to set up alarms and get notified of any issues.Enable CloudTrail: CloudTrail records API calls made to EventBridge, which can be useful for troubleshooting and auditing purposes. Enable CloudTrail and review the logs in case of any issues.Use CloudWatch Logs: EventBridge allows you to log events to CloudWatch Logs, which can help in troubleshooting and debugging your event-driven architecture. Use CloudWatch Logs to view the details of incoming events and troubleshoot any errors.Use Amazon EventBridge Console: The Amazon EventBridge console provides a visual representation of your event buses, rules, and targets. Use the console to monitor the flow of events and troubleshoot any issues with your event-driven architecture.
Comparing AWS EventBridge with Alternatives
There are a few alternatives to AWS EventBridge, and here we will compare it with some of the popular options:
- AWS Simple Queue Service (SQS): AWS SQS is a managed message queue service that allows decoupling of components in a distributed system. It is a reliable and highly available service that can handle large volumes of messages. Unlike EventBridge, SQS does not have built-in event routing and transformation capabilities. Users have to handle these functionalities themselves by using other AWS services like AWS Lambda or Amazon Simple Notification Service (SNS). This can require additional development effort and may not be suitable for complex event-driven architectures.
- Apache Kafka: Apache Kafka is an open-source distributed event streaming platform. It is highly scalable and can handle large volumes of events. Kafka provides features such as event routing and transformation through its Streams API. However, setting up and managing Kafka clusters can be complex and requires a significant amount of resources. It may not be suitable for smaller applications or those without dedicated DevOps resources.
- Google Cloud Pub/Sub: Google Cloud Pub/Sub is a fully managed event streaming service provided by Google Cloud Platform. It offers similar capabilities to AWS EventBridge, such as event routing and transformation. However, it is limited to Google Cloud services and does not have integrations with third-party applications. This can be a drawback for users who need to connect their custom applications or services from other cloud providers.
- Azure Event Grid: Azure Event Grid is a serverless event routing service offered by Microsoft Azure. Like AWS EventBridge, it supports event filtering, routing, and transformation. However, it is limited to Azure services and does not have integrations with third-party applications. It also has a lower event processing limit compared to AWS EventBridge. This can be a limitation for applications that require high event processing volumes.
Real-world Use Cases
- Automated Workflows and Process Automation: AWS EventBridge can be used to create automated workflows and processes, helping organizations to streamline their operations and reduce manual work. For example, an e-commerce company can use EventBridge to trigger a series of events when a customer places an order, such as sending a confirmation email, updating inventory, and initiating the shipping process.
- Serverless Architecture and Microservices: EventBridge is a key component in building serverless architectures and microservices on AWS. It allows different services and applications to communicate with each other through events, reducing the need for complex integrations and point-to-point connections. This enables organizations to build scalable and flexible systems that can handle large volumes of data and events.
- Data Ingestion and Processing: EventBridge can be used for real-time data ingestion and processing, making it an ideal solution for streaming data from various sources. For example, a media company can use EventBridge to ingest and process user interaction data from their website, social media, and mobile apps in real-time, allowing them to make data-driven decisions and personalize user experiences.
- Monitoring and Alerting: EventBridge can be used for monitoring and alerting in cloud environments. It can receive events from different AWS services, such as Amazon CloudWatch, and trigger actions or send alerts based on predefined rules. This allows organizations to proactively monitor their resources and respond to any issues or anomalies in real-time.
- DevOps and CI/CD Pipelines: EventBridge can be integrated with DevOps tools and services to automate the deployment and management of applications. It can receive events from source code repositories, build and test systems, and deployment tools, triggering actions and updates as needed. This enables organizations to build efficient and reliable CI/CD pipelines for their software development processes.
- Cloud Infrastructure Management: EventBridge can be used to manage and automate cloud infrastructure, such as launching and terminating instances, scaling resources, and managing backups. This helps organizations to optimize their cloud resources and reduce costs by automatically scaling up or down based on demand.
- IoT Applications: EventBridge can be used for building event-driven IoT applications. It can receive events from IoT sensors and devices, triggering actions and updates in real-time. For example, a smart home system can use EventBridge to control and automate devices based on events, such as turning on lights when a person enters a room.
- Data Analytics and Machine Learning: EventBridge can be integrated with AWS services for data analytics and machine learning, such as Amazon Kinesis and Amazon SageMaker. This allows organizations to capture and process events in real-time and use the data for training machine learning models and making data-driven decisions.
- Chatbots and Voice Assistants: EventBridge can be used to build chatbots and voice assistants that can respond to user requests and trigger actions based on events. For example, a customer service chatbot can use EventBridge to access customer information and provide personalized responses based on events, such as a customer placing an order or requesting a refund.
- Third-Party Integrations: EventBridge can be used to integrate with third-party services and applications, such as CRM systems, marketing automation tools, and payment gateways. This enables organizations to automate workflows and processes across different systems, improving efficiency and reducing manual work.
Summary
AWS EventBridge stands out as a versatile and robust service designed to facilitate the creation and management of event-driven architectures in the cloud. By providing a centralized event bus with seamless integration capabilities, it enables developers to connect various AWS services, third-party applications, and custom applications through events. This fosters the development of scalable, resilient, and real-time responsive systems.
EventBridge’s core features—such as flexible event routing, real-time event processing, and event filtering—make it an essential tool for building efficient and dynamic workflows. Its integration with AWS services like Lambda, S3, and CloudWatch further enhances its utility, simplifying complex event-driven processes. The service’s cost-effectiveness, ease of use, and support for multi-cloud environments ensure that organizations can leverage it without significant overhead.
Moreover, AWS EventBridge’s schema registry and discovery capabilities promote data consistency and interoperability, which are crucial for complex data integration tasks. The ability to automate processes, manage cloud infrastructure, and build serverless architectures underscores EventBridge’s role in modern cloud computing.
When comparing EventBridge to alternatives like AWS SQS, Apache Kafka, Google Cloud Pub/Sub, and Azure Event Grid, its seamless AWS ecosystem integration, coupled with extensive features for event routing and processing, offers a distinct advantage. This makes EventBridge particularly appealing for organizations already invested in AWS or seeking a fully managed event bus service.
In real-world scenarios, EventBridge proves invaluable across various domains, including automated workflows, data ingestion and processing, DevOps, IoT applications, and more. Its ability to trigger actions based on events enables businesses to streamline operations, enhance real-time data handling, and build responsive systems.
Overall, AWS EventBridge is a critical component for developers aiming to implement event-driven architectures in the cloud. Its comprehensive feature set, ease of integration, and support for diverse use cases make it a powerful tool for building scalable, flexible, and efficient cloud-native applications.